Data lakes and Athena!
In an age where companies are heavily investing in data to gain insights into their business, more and more are building data lakes to store unstructured data for analysis. This data has an audience of diverse interests, from data scientists using it to power ML models or generate benchmarks, to Business Analysts seeing metrics on company/project performance. One approach i’ve used is using AWS Athena and S3 for the storage and querying of data within a data lake.
This blog post is to show how simple it is for companies on AWS to hook up a data lake and start gaining insights into their data. It’s taking the fact that companies already are on AWS, have some data in a data lake that’s stored correctly (will get to that later) and have a data analytics/BI platform like Domo, Tableau or Looker setup.
First things first, let’s talk about a data lake. I won’t go into the hows and the whys of data lakes in general, so let’s just start with a simple lake example. You have been capturing JSON/CSV/AVRO/ORC or Parquet files and storing them on S3. For more info on what a data lake is, please check the AWS write up here.
s3://my-data-lake/raw/cool_data_source/dt=2020–03–06/data.parquet
Depending on the volume of the data in its raw format, you may want to further refine it by processing it or perhaps building aggregations, but for the purpose of the example, we’ll assume that raw is fine. A potential reasoning of why raw data may not be suitable for Athena, would be capturing data in small files on S3. This can cause a lot of throttling of s3 requests and poor performance in Athena query times. A general rule of thumb is to ensure data files are compressed and aim for around a 128mb file size.
So let’s look at the schema for cool_data_source. Opening it up in Spark and investigating (df.printSchema() is fine for this stage), you are left with the following schema:
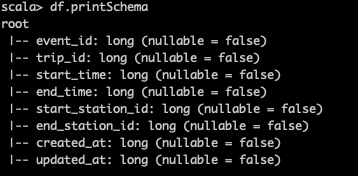
By leveraging the AWS stack, we can use AWS Glue meta store via Athena to build out a table that represents this data in a hive compatible external table. Here’s the example DDL for the data source. We’ll use the default database for this example, but you can easily create your own.

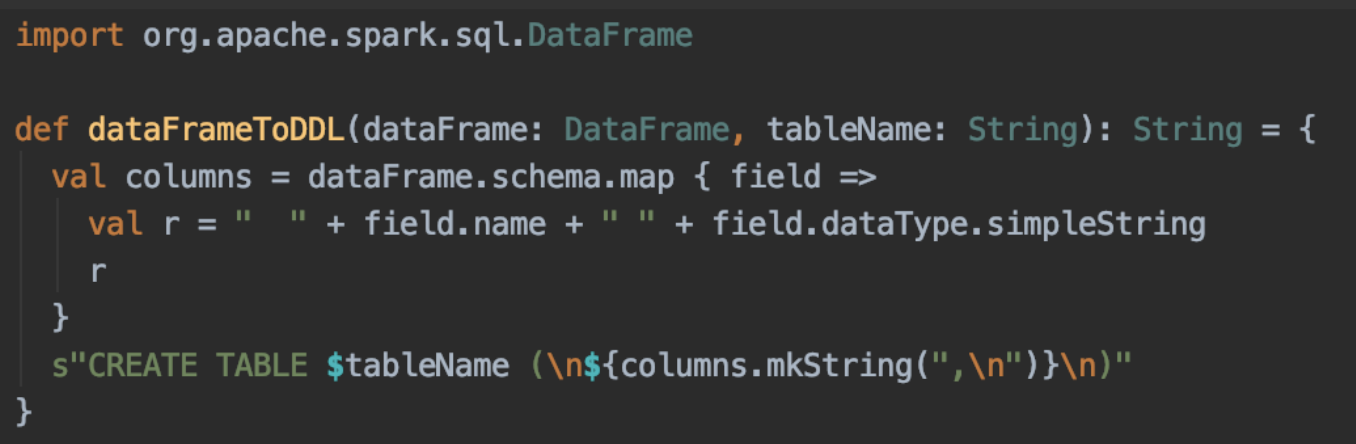
You can hand craft these DDLs, but it’s also pretty easy to build them out dynamically via Spark
Since the data is partitioned, we need to tell the meta store to load up any partitions we haven’t seen before. This is pretty easy to do using the msck repair table from hive, but if your table has a lot of partitions, it’s sometimes better to just add the specific partitions (bonus points if you are using aws glue crawlers or if you have something like airflow automatically doing this):
So far, we have data on a data lake that’s now loaded up into Athena and ready for querying. Athena, like presto, is accessible via a JDBC connection, which means we can hook it up to most BI tools (personally I’ve used Domo, Tableau, Looker, DBBeaver and Superset and have found them all to be easy enough to hook up).